1.什么是状态码301301 Moved Permanently(永久重定向) 被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址...
”python scrapy爬虫遇见301“ 的搜索结果
def demo():headers = {'Accept':'xxxx','Accept-Encoding':'xxxx','Accept-Language':'xxxx','Connection':'xxxx','Host':'xxxx','Upgrade-Insecure-Requests':'x','User-Agent':'Mozilla/5.0 (Windows NT 10.0;...
pythonscrapy爬虫实例Python爬虫Scrapy实例
Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。 小刮刮是一个为遍历爬行网站、分解获取数据而设计的应用程序框架,它可以应用在广泛领域:数据挖掘、信息处理和或者...
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作。运行环境:电脑上已经安装了python(环境变量path已经设置好),以及scrapy模块,IDE为Pycharm 。操作如下:一、建立Scrapy模板。进入自己的工作目录,...
首先得有一个Scrapy项目,我在Desktop上新建一个Scrapy的项目叫test,在Desktop目录打开命令行,键入命令:scrapy startproject test1目录结构如下:打开Pycharm,选择open选择项目,ok打开如下界面之后,按alt + 1...
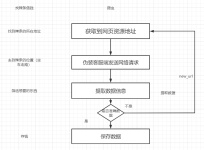
遇到301状态码通常表示重定向,可能是因为您的爬虫被网站检测到并阻止了进一步的访问,导致爬虫被关闭了。此时您可以尝试以下方法: 1. 添加请求头,模拟浏览器访问,避免被网站检测到。 2. 调整爬虫的访问频率及...
解决方法:setting.pyROBOTSTXT_OBEY = True 改成False原因:scrapy抓包时的输出就能发现,在请求我们设定的url之前,它会先向服务器根目录请求一个txt文件这个文件中规定了本站点允许的爬虫机器爬取的范围(比如你不...
2018-07-26 09:37:28 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: jizhi)2018-07-26 09:37:28 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1...
在scrapy爬取数据时,遇到重定向301/302,特别是爬取一个下载链接时,他会直接重定向并开始下载,在下载之后才会返回爬取的链接,这时候就需要中止重定以下302都可以换成301,是一样的。
大家好,本篇文章我们来看一下强大的Python爬虫框架Scrapy。Scrapy是一个使用简单,功能强大的异步爬虫框架,我们先来看看他的安装。Scrapy的安装Scrapy的安装是很麻烦的,对于一些想使用Scrapy的人来说,它的安装...

下一页ajax动态生成 该怎样解决 求详细解答,遇见下一页是ajax动态生成 弄了几天了 还是搞不懂
原标题:Python爬虫:Scrapy框架的安装和基本使用大家好,本篇文章我们来看一下强大的Python爬虫框架Scrapy。Scrapy是一个使用简单,功能强大的异步爬虫框架,我们先来看看他的安装。Scrapy的安装Scrapy的安装是很...

一、介绍 今天主要介绍的是微博客户端在登录时出现的四宫格手绘验证码,不多说直接看看验证码长成什么样。 二、思路 1、由于微博上的手绘验证码只有四个宫格,且每个宫格之间都有有向线段连接,所以我们可以判断四...
大家好,本篇文章我们来看一下强大的Python爬虫框架Scrapy。Scrapy是一个使用简单,功能强大的异步爬虫框架,我们先来看看他的安装。Scrapy的安装Scrapy的安装是很麻烦的,对于一些想使用Scrapy的人来说,它的安装...
给大家带来的一篇关于Python爬虫相关的电子书资源,介绍了关于Python、网络爬虫方面的内容,本书是由人民邮电出版社出版,格式为PDF,资源大小5.54 MB,瑞安·米切尔编写,目前豆瓣、亚马逊、当当、京东等电子书综合...

大家好,本篇文章我们来看一下强大的Python爬虫框架Scrapy。Scrapy是一个使用简单,功能强大的异步爬虫框架,我们先来看看他的安装。Scrapy的安装Scrapy的安装是很麻烦的,对于一些想使用Scrapy的人来说,它的安装...
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。 ...
作者在日常学习工作中遇见的基于Django3.x使用Scrapy 2.4.0 的汇总,依据Scrapy 2.4.0 官网进行的翻译和应用举例,根据自己的实际情况选择目录进行阅读。 后续会不断进行更新内容到这个目录,望君收藏。 【Scrapy ...
scrapy.Request Missing scheme in request url:
大家好,本篇文章我们来看一下强大的Python爬虫框架Scrapy。Scrapy是一个使用简单,功能强大的异步爬虫框架,我们先来看看他的安装。Scrapy的安装Scrapy的安装是很麻烦的,对于一些想使用Scrapy的人来说,它的安装...
在使用Scrapy框架中总是遇到这类问题,在此留下记录,方便查阅、三种解决方式:解决(一)在Request中将scrapy的dont_filter=True,因为scrapy是默认过滤掉重复的请求URL,添加上参数之后即使被重定向了也能请求到正常...
大家好,本篇文章我们来看一下强大的Python爬虫框架Scrapy。Scrapy是一个使用简单,功能强大的异步爬虫框架,我们先来看看他的安装。Scrapy的安装Scrapy的安装是很麻烦的,对于一些想使用Scrapy的人来说,它的安装...
一开始我是想要从2345天气预报网上爬取某城市的历史天气数据,然后在搭建好scrapy爬虫框架后启动爬虫没有任何的数据,之后看CSDN论坛大家的博客加入refer后没有了没有refer none的错误了,但还是没有爬下来数据,...
查询运行的容器实例hxb@omg:~$ sudo docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES2f61e681e7a8 ubuntu...
推荐文章
- python入门(13)异常与文件_except filenotfounderror:-程序员宅基地
- Android面试攻略_详细了解在当今的社会里android工程师应具备什么的技能?并能详细说说自己的见解。-程序员宅基地
- Zendframework 1.6整合Smarty_setting private or protected class member is not a-程序员宅基地
- Qt-装饰者模式_qt装饰模式-程序员宅基地
- 新开普掌上校园服务管理平台service.action RCE漏洞复现 [附POC]-程序员宅基地
- 基于 Milvus 的音频检索系统-程序员宅基地
- 331、基于51单片机智能红外遥控暖风机温度无线蓝牙远程控制系统设计(程序+原理图+配套资料等)_红外感应暖风机自动控制系统设计-程序员宅基地
- Android自定义圆角矩形图片ImageView_android 矩形圆角imageview-程序员宅基地
- 又见回文 字符串-程序员宅基地
- switch的参数可以是什么类型?_switch的参数有哪些-程序员宅基地